|
|
Welcome to the research group DILiS
Data Integration in the Life Sciences (DILiS)
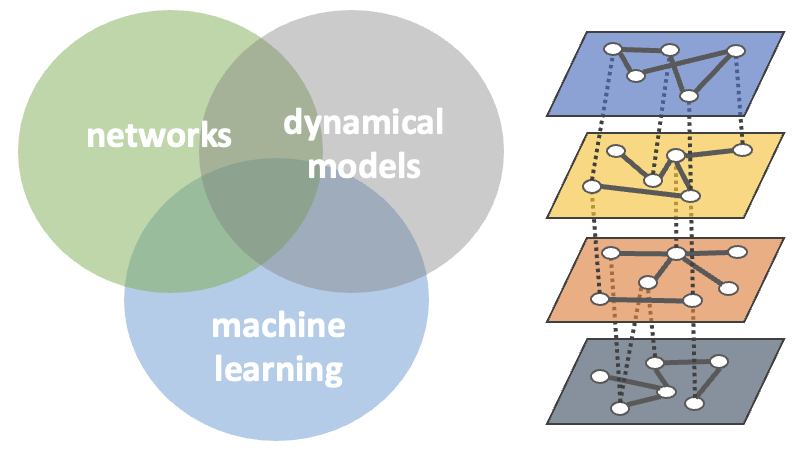 For many problems in the life sciences, different types of data have been generated and provide different views. Each data layer comes with its own limitations, errors and biases, so their integrative analysis is key for robust conclusions in order to understand complex phenomena. Our research group Data Integration in the Life Sciences (DILiS) leverages different methods for data analysis: machine learning enables the detection of patterns from unstructured data, but large deep learning models usually require large amounts of data. Networks allow representing interactions between entities and are highly informative. Straightforwardly, they enable the combined analysis of different data views. Dynamical models capture temporal behaviors and complex, intricate relationships. In addition to using these methods and their strengths separately, we are interested in combining machine learning, network-based analysis and mathematical modeling of dynamic processes. We are thereby especially interested in how the latter two can be used to include prior information (domain knowledge) into the prediction pipelines. Applications stem mainly from a biomedical background, such as drug response prediction, and we focus on integrating different kinds of data with biomolecular, "multi-omics" data.
For many problems in the life sciences, different types of data have been generated and provide different views. Each data layer comes with its own limitations, errors and biases, so their integrative analysis is key for robust conclusions in order to understand complex phenomena. Our research group Data Integration in the Life Sciences (DILiS) leverages different methods for data analysis: machine learning enables the detection of patterns from unstructured data, but large deep learning models usually require large amounts of data. Networks allow representing interactions between entities and are highly informative. Straightforwardly, they enable the combined analysis of different data views. Dynamical models capture temporal behaviors and complex, intricate relationships. In addition to using these methods and their strengths separately, we are interested in combining machine learning, network-based analysis and mathematical modeling of dynamic processes. We are thereby especially interested in how the latter two can be used to include prior information (domain knowledge) into the prediction pipelines. Applications stem mainly from a biomedical background, such as drug response prediction, and we focus on integrating different kinds of data with biomolecular, "multi-omics" data.
Get to know our group
DILIS Web Utilities
- WebTopicList - all topics in alphabetical order
- WebChanges - recent topic changes in this web
- WebNotify - subscribe to an e-mail alert sent when topics change
- WebRss, WebAtom - RSS and ATOM news feeds of topic changes
- WebPreferences - preferences of this web
Edit | Attach | Print version | History: r10 < r9 < r8 < r7 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r10 - 26 Feb 2025, Kb1223fuUserTopic
- This page was cached on 30 Mar 2025 - 16:31.
Ideas, requests, problems regarding Foswiki? Send feedback