|
|
Page ArtCluster
Artikel Cluster BenutzungSysteme
Die einzelnen Nodes des "Gaia" Clusters sind auf mehrere Bladecenter verteilt:| Bladecenter | nodes | CPUs | Memory | OS | Aufgabe |
|---|---|---|---|---|---|
| - | gaia | 8 | 32 GB | Lenny | Vorrechner |
| bc5 | gaia1 - 10 | 8 | 8 GB | Lenny | Berechnungen |
| bc4 | gaia11 - 15 | 8 | 8 GB | Lenny | Berechnungen |
| bc4 | gaia16 - 20 | 8 | 16 GB | Lenny | Berechnungen |
| bc3 | gaia21 - 22 | 8 | 16 GB | Lenny | Berechnungen |
| bc3 | gaia23 - 29 | 8 | 32 GB | Squeeze | Berechnungen |
| bc7 | gaia30 - 32 | 8 | 32 GB | Lenny | Berechnungen |
| - | gaia33 - 34 | 8 | 32 GB | Lenny | Ignis |
| - | gaia35 - 36 | 8 | 16 GB | Lenny /Squeeze | Ignis |
| - | gaia37 - 42 | 12 | 72 GB | Lenny | Berechnungen |
Belegung
Die Zuordnung der einzelnen Nodes zu Personen/Projekten war? über die Seite Belegung der Gaia-Nodes ersichtlich - gegenwärtig scheint diese Seite nicht mehr zu existieren, ist sie umgezogen? Einen gewissen Aufschluß gibt die Prozessauslastung, dies kann jedoch nur einen Anhaltspunkt darstellen.Status
Ein Systemmonitoring erfolgt mit Munin.Überlastung
Linux ist leider nicht unbegrenzt belastbar. Eine Überlastsituation wird nicht elastisch abgefangen, und "nur" mit Performanceeinbußen quittiert, sondern führt zuverlässig dazu, daß die Node noch nicht einmal mehr in der Lage ist, ihre grundlegende Selbsterhaltung zu betreiben. Aus diesem Zustand sind die nodes, regelmäßig nur durch einenreboot herauszuholen. Gerade laufende Berechnungen sind dadurch entsprechend unkontrolliert terminiert.
Ein Beispiel: gaia29, 32GB Memory, 2G swap. Es werden mehr Prozesse gestartet, als Kerne zur Abarbeitung zur Verfügung stehen. (Die Load gibt in gewissem Maß eine Aussage dazu, wieviele Prozesse gerade warten).
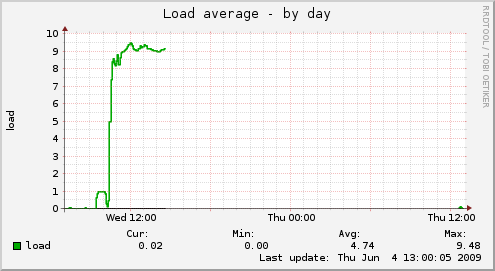
Die gestarteten Prozesse wachsen in ihrem Memoryverbrauch zügig, durchbrechen die Grenze des physisch vorhandenen Speichers, die 2G swap sind nicht in der Lage das aufzufangen.
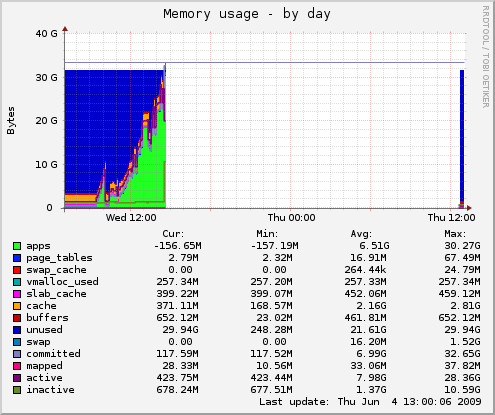
Das System dreht sich fortan mit Speicherproblem auf der Platte.

Zu überprüfen wäre, ob die gestarteten Programme einmal allozierten Speicher auch wieder freigeben, oder, wenn sie sich hierdrin korrekt verhalten, wieviele der Berechnungsprozesse das Systen verträgt. Solange der Speicherverbrauch mehr oder weniger stetig anwächst, ist jedoch auch bei reduzierter Anzahl von Prozessen die Grenze absehbar.
Nachfolgend eine Darstellung, wie sich der gleiche Prozess verhät, wenn die Belastung etwas besser zum System passt. Sehr hübsch
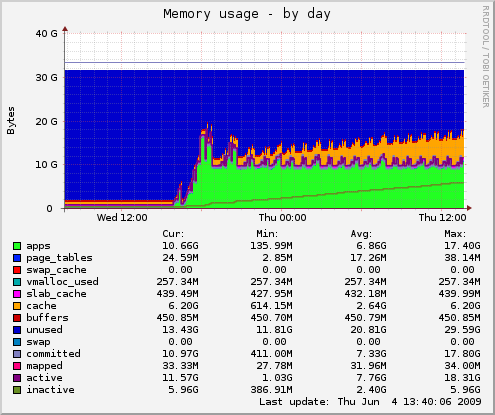
Wir werden aus dem für Zwischenergebnisse und Berechnungsdaten vorgesehenem Plattenbereich unter /export/local-1 versuchsweise 20G abzweigen und dem Swapspace zuordnen, damit die Maschine nicht ganz so schnell "gegen die Wand rennt", sondern etwas Karenzzeit zum reagieren läßt.
Technisches...
Queueing/Batch Mechanismus
Zum Queueingmechanimsus ist ein Link oder eine Beschreibung sicherlich sinnvoll - mir liegt zur Benutzerseite bisher nichts vor.Querying all nodes
Auf Bitte eines Benutzers ist hier ein (sehr einfaches) script angehängt, mit dem ein Prozess auf allen gaia nodes gestartet werden kann. Die Ausgabe wird in Einzeldateien pro Clusternode umgelenkt, die in einem nach der Prozessid benannten Directory gesammelt werden. (Letzteres, um einen eindeutigen Namen für das Verzeichnis zu haben.)- cycle: Script to send a command to every gaia node, collecting the output in individual files per node.
./cycle uptime aufgerufen werden, um z.b. eine Kurzübersicht über die Auslastung der einzelnen nodes zu erhalten.
Ist es nicht ausfürbar, so lautet der Aufruf sh ./cycle uptime.
Ein Passwort nimmt das script nicht mit - hierfür gibt es abgesicherte Vorgehensweisen, die eine solche Behandlung per script überflüssig machen: -
ssh-agentmacht bei Verwendung von passwortgesicherten ssh keys die mehrfache Eingabe des Passwortes überflüssig. -
kinitdient dazu, ein Kerberos-Ticket zu generieren, mittels dessen dann innerhalb des lokalen Gütigkeitsbereiches ebenfalls ohne separate Authentifizierung gearbeitet werden kann.
Nachfolgend noch ein Einzeiler, der dieses Script verwendet, um auf Benutzerprozesse reduzierte process listings einzusammeln, mit denen sich schnell ersehen läßt, wo noch eigene Prozesse liegengeblieben sind, respektive welche Nodes im Augenblick nicht aktiv von anderen Benutzern verwendet werden.
- userps.sh: Collect a listing of user processes per node.
ls -l zeigt an der Charakteristischen Filelänge der Dateien, die nur den Prozesslistingkopf enthalten, auf welcher node "gar nichts" los ist.)
Dateisystem
Hintergrund
die Verwendung von NFS (Network File System) ist in einer Umgebung, in der concurrierend auf die Daten im Filesystem geschrieben und gelesen werden soll, nicht unproblematisch. Der Grund hierfuer liegt in der cache coherency, die in solchen Faellen nur durch eine erzwungene Serialisierung der Anfragen sicherstellbar ist. Dies kann Applikationsseitig erreicht werden, indem die Dateien mitO_SYNC respektive
O_FSYNC geöffnet werden.
Administrationsseitig kann dies auch pro NFS-export aktiviert werden.
In beiden Fällen hat dies jedoch deutliche Auswirkungen auf die Performance,
es werden sowohl schreibende, als auch lesende Prozesse "gnadenlos" aufgehalten. Insbesondere wenn die
Schreiboperationen haeufig und in kleinen Teilen erfolgen, wird dies deutlich.
Lösungsansätze
Es gibt mehrere Methoden, mit denen in Clusterumgebungen mit dieser Problematik umgegangen wird. Der gewählte Weg hängt dabei sowohl von den lokalen Gegebenheiten, dem gewählten OS (es gibt weniger fehlerbehaftete NFS-Implementierungen, die Grundproblematik der Cachekohärenz ist jedoch protokollimmanent).- pragmatisch: der Schreibvorgang wird auf den Fileserver verlagert. Dieser ist damit über alle Schreibvorgänge informiert, die NFS eigenen Mechanismen des read-caches greifen weiterhin und funktionieren zufriedenstellend.
- pragmatisch 2: Jedem NFS-Schreibvorgang wird ein Prozess nachgeschaltet, der auf dem Fileserver einen "touch" der beschriebenen Datei durchführt. Dies erreicht, dass der schreibende Client, der bis dahin nur seinen lokalen write-cache gefüllt hat, gezwungen wird den Inhalt an den Server weiterzureichen. Der read-cache der Clients funktioniert weiterhin, der Performance Hit hängt stark von der schreibenden Applikation ab. Da weiterhin per NFS geschrieben wird, sind die Bugs der jeweiligen Implementation damit jedoch nicht umgangen.
- Rundumschlag: das NFS Protokoll wird zumindest für den schreibenden Prozess durch ein anderes, besser geeignetes Protokoll ersetzt, in dem beispielsweise die Methoden eines Object Request Brokers auf Filesysteme angewandt werden.
Lösung
Da nahezu alle Probleme gelöst sind, wenn der Schreibvorgang direkt auf dem Fileserver stattfindet, haben wir einen Weg beschritten, der dieses ermöglicht, ohne daß die schreibende Applikation von diesem Vorgang Kenntnis haben muß. Die worker Prozesse auf den einzelnen nodes schreiben das Ergbnis ihrer Berechnungen nicht mehr auf das per NFS gemountete/home/cocktail/... Verzeichnis, sondern in ein lokal auf dem jeweiligen Knoten liegendes Verzeichnis unter /export/daten/. Prozesse, die von anderen Knoten aus lesend auf diese Daten zugreifen sollen, finden sie auf allen gaia-nodes unter /data/.
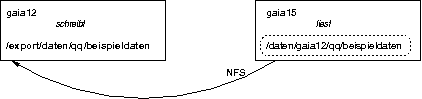
Tools
Kopieren von Daten
Um Dateien von einer Node zur anderen zu kopieren bietet sich scp(1) an, wenn jedoch ganze Dateibäume synchron gehalten werden sollen ist es schnell überfordert. Das Programm rsync(1) überprüft vor dem Kopieren, ob die Datei auf dem Zielsystem bereits vorhanden ist, und überspringt sie gegebenenfalls. Bei größeren Datenmengen lohnt sich ein Blick auf bbcp, mit dem darüber hinaus die Übertragungsparameter optimiert werden können. Hanushevsky et al. 2001 (Presentation).Comments


| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
cycle | manage | 633 bytes | 04 May 2010 - 11:00 | UnknownUser | Script to send a command to every gaia node, collecting the output in individual files per node. |
| |
userps.sh | manage | 165 bytes | 04 May 2010 - 11:03 | UnknownUser | Collect a listing of user processes per node. |
- User Reference
- BeginnersStartHere
- EditingShorthand
- Macros
- MacrosQuickReference
- FormattedSearch
- QuerySearch
- DocumentGraphics
- SkinBrowser
- InstalledPlugins
- Admin Maintenance
- Reference Manual
- AdminToolsCategory
- InterWikis
- ManagingWebs
- SiteTools
- DefaultPreferences
- WebPreferences
- Categories
Ideas, requests, problems regarding Foswiki? Send feedback