|
|
You are here: Foswiki>ABI Web>ThesesHome>ThesisMCRazer>ThesisMCRazerWeeklyReports>ThesisMCRazerParallelOptions (14 Feb 2010, mriese)Edit Attach
Page ThesisMCRazerParallelOptions
| Option | Details and Options | Pro | Contra | TBB? |
|---|---|---|---|---|
| Parallelize by Genome | ||||
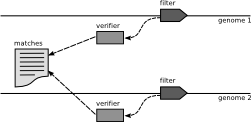 |
Filter and verifiere copy per genome | needs a lot of memory | ||
| prob. not cache local as it needs to switch between genomes | ||||
| Parallelize by Reads | ||||
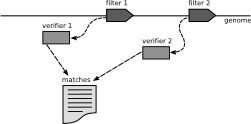 |
coupled filter-verifier-pairs | no spin lock for verifier | ||
| each pair over a subset of the reads | filter is parallel | |||
| a) pairs operate independent from each other | no regulation necessary | one might run away (cache) | ||
| b) pairs operate in the same window | little regulation, simple find() | waiting times | ||
| c) Distance between pairs is restricted | waiting times, regulation for more than two pairs get complex | |||
| distance between filter and verifier fixed ? | ||||
| Pipeline | ||||
 |
One filter over all reads, verification parallelized | spin locks for verifier necessary, probably bad use of capacity in repeats | ||
| a) windows | simple find() | filters are not parallel (problem with high number of cores) | ||
| b) tokens | complex find() | TBB | ||
| c) distance between filter and verifier | complex find() | |||


| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
RazerS-Piktogram-Parallel-Hybrid-sm.png | manage | 4 K | 03 Feb 2010 - 09:37 | UnknownUser | |
| |
RazerS-Piktogram-Parallel-by-Genome-sm.png | manage | 5 K | 03 Feb 2010 - 09:28 | UnknownUser | |
| |
RazerS-Piktogram-Parallel-by-Reads-sm.png | manage | 5 K | 03 Feb 2010 - 09:37 | UnknownUser |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Edit | Attach | Print version | History: r4 < r3 < r2 < r1 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r3 - 14 Feb 2010, mriese
Ideas, requests, problems regarding Foswiki? Send feedback